
A line stops in the middle of a run. Operators gather around the fault light. Maintenance gets called off another job. Supervisors start reworking the schedule before they even know whether the problem is a sensor, a drive, a jam, or a control issue. That scene is familiar in small to mid-sized plants, especially where semi-automated equipment carries most of the throughput and a single station failure can choke the whole process.
In that environment, mean time between failures isn't just a reliability term from an engineering handbook. It's a practical way to judge whether your equipment is supporting production or fighting it. If you provide manufacturing solutions to optimize production and services, MTBF is one of the clearest ways to connect machine behavior to uptime, labor use, maintenance planning, and return on investment.
Table of Contents
- The True Cost of Unplanned Downtime
- What Is MTBF and Why It Matters in Manufacturing
- Calculating MTBF with Real-World Examples
- MTBF and Its Relationship to Other Key Metrics
- Common Misuses and Data Pitfalls to Avoid
- Practical Strategies to Improve Your MTBF
- MTBF in Medical Device Manufacturing and GMP
The True Cost of Unplanned Downtime
A production line rarely fails at a convenient time. It stops during a customer build, during shift change, during a rush order, or when the one technician who knows the station best is already tied up elsewhere. The direct repair cost hurts, but the bigger damage usually comes from the chain reaction that follows: idle labor, rescheduling, scrap risk, delayed shipments, and a team forced into reactive decisions.
That pattern shows up at scale across industry. The world's 500 biggest companies lose nearly $1.4 trillion annually due to unplanned downtime, which equals 11% of their total operational capacity, according to NetSuite's discussion of mean time between failure. Plant managers at smaller operations may not be dealing with losses on that scale, but the mechanism is the same. When a critical asset drops out unexpectedly, production capacity disappears immediately.
What downtime looks like on the floor
On a semi-automated line, one failed subsystem can create several kinds of waste at once:
- Waiting labor: Operators stand by while maintenance diagnoses the problem.
- Blocked flow: Upstream work-in-process builds up and downstream stations starve.
- Quality risk: Restart conditions aren't always as stable as steady-state production.
- Schedule disruption: Supervisors move people and jobs instead of running the plan.
Unplanned downtime turns a production problem into a management problem within minutes.
This is why MTBF matters to operations leaders. It gives you a way to stop managing failures as isolated events and start treating them as a pattern. A machine that fails often doesn't just cost repair hours. It consumes management attention, operator confidence, and production stability.
Why reactive maintenance keeps plants stuck
Plants that stay in firefighting mode usually know their machines are unreliable. What they often don't have is a clean measure of how unreliable, and whether the problem is getting better or worse. MTBF gives maintenance and production a common language. It answers a basic question that matters on every shift: how long does this asset typically run before the next failure interrupts production?
That answer changes planning. Instead of waiting for the next stop, teams can schedule intervention earlier, stock the right parts, and decide whether an upgrade is justified. In many cases, pairing reliability tracking with structured maintenance support services is what pulls a plant out of reactive work and back into predictable output.
What Is MTBF and Why It Matters in Manufacturing
Mean time between failures is the average operating time between one failure and the next for a repairable system. In engineering terms, MTBF = T/k, the ratio of cumulative operating time to the total number of failures during a stated period, as defined by ScienceDirect's engineering reference on mean time between failure.
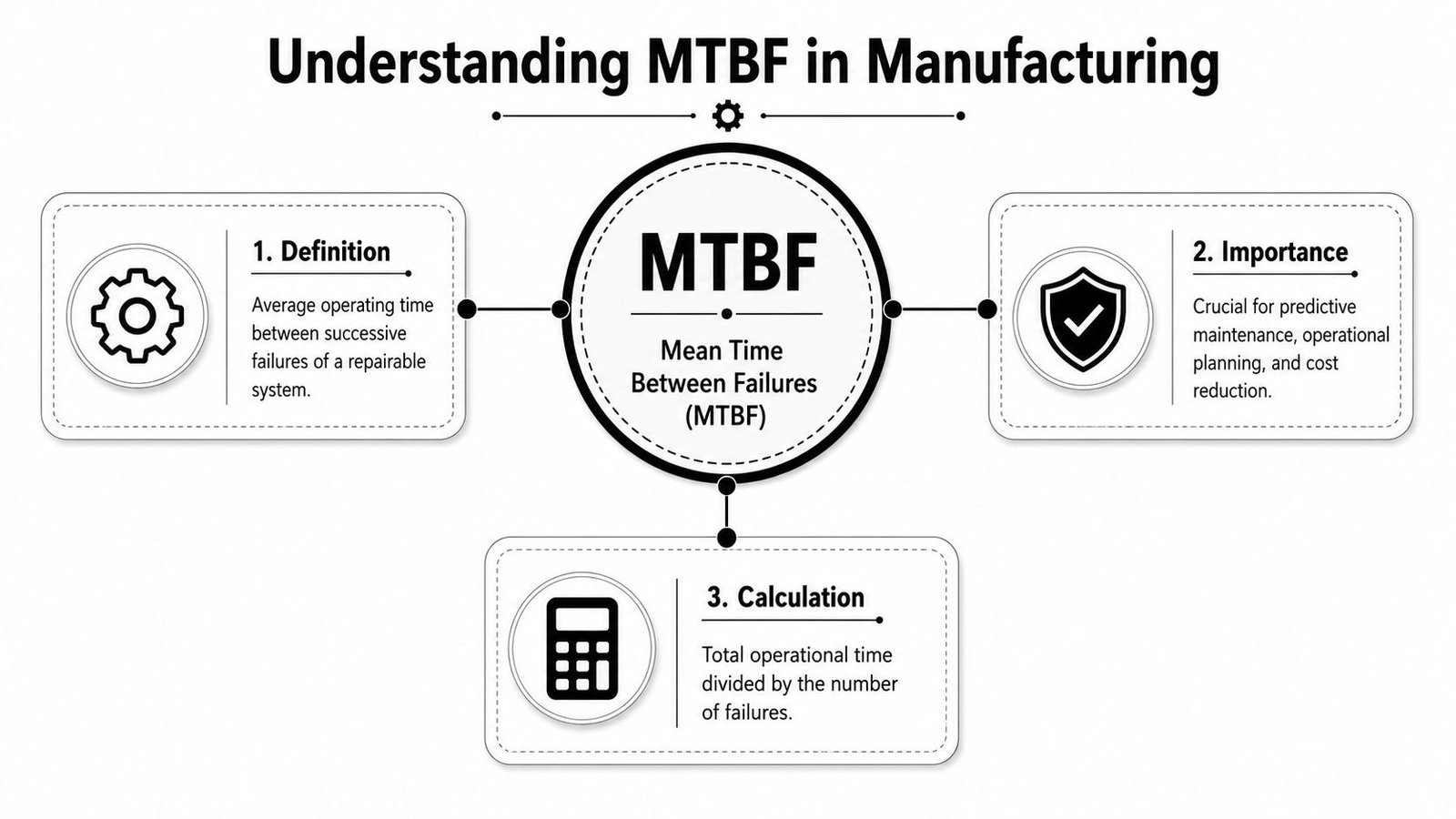
For manufacturing, the simplest way to think about it is this: if a station runs, gets repaired when it fails, and then returns to production, MTBF tells you the average run time between those failures. That's why it fits assets like conveyors, assembly cells, indexed fixtures, pump systems, CNC equipment, and semi-automated workstations.
Why plant managers should care
MTBF matters because it translates machine history into a planning signal. A higher MTBF usually means fewer interruptions, fewer emergency callouts, and a better chance of hitting schedule without overtime or constant reshuffling. It also helps operations leaders compare equipment objectively.
If two stations do the same job but one fails far more often, MTBF exposes that quickly. That makes it easier to justify a controls update, a fixture redesign, better sensors, or a maintenance change based on production impact instead of frustration.
Practical rule: If the asset can be repaired and returned to service, MTBF belongs in the conversation.
MTBF is not the same as MTTF
Many teams often make a mistake here. MTBF applies to repairable systems. MTTF applies to non-repairable items. That sounds simple, but in real plants the boundary gets blurry because one machine can contain both.
A semi-automated medical assembly station is a good example. The station itself is repairable, so MTBF fits the machine. A single-use component processed by that machine isn't repaired after failure, so MTTF is the better metric for that item.
Use this rule of thumb:
- Use MTBF for machines, cells, and repairable production equipment.
- Use MTTF for items that are discarded and replaced after failure.
- Separate the two when building maintenance plans or compliance records.
A lot of academic material stops at the formula. On the plant floor, the value is in what MTBF lets you do next. It helps you anticipate interruptions, plan labor, align maintenance timing with production reality, and make automation investments that improve throughput without giving up flexibility.
Calculating MTBF with Real-World Examples
The formula is straightforward. The hard part is deciding what data counts and how to apply the result in a real operation. For most plants, the cleanest starting point is a single asset with a clear run history.
Start with one machine and one time window
Take the operating hours for the period you want to analyze. Count the failures recorded in that same period. Then divide total operating time by total failures.
The standard empirical form is simple:
- Choose the asset: Pick one repairable machine or station.
- Define the period: Use a consistent operating window from your logs.
- Count only real failures: Include events that required repair to restore function.
- Do the math: Total operational hours divided by number of failures.
A classic example from field maintenance uses a pump with 1,000 operational hours and 4 failures, which yields an MTBF of 250 hours, as shown in eMaint's explanation of MTBF.
That number becomes useful when it changes behavior. If your line depends on that pump, a 250-hour MTBF tells you the asset needs attention long before anyone wants to wait for the next breakdown.
Translate the number into production language
Managers don't run plants with formulas alone. They run with shifts, staffing, work orders, and shipment dates. That's why MTBF has to be interpreted in operating terms.
A useful benchmark from Symestic's explanation of failure rate and MTBF makes the difference clear:
- An MTBF of 50 hours means a machine fails roughly once every two production shifts.
- An MTBF of 500 hours means failure happens only about once per month.
That gap matters. The second machine doesn't just fail less often. It creates a different kind of production environment. Supervisors can schedule around it. Maintenance can work proactively. Operators trust it.
A small MTBF improvement can feel minor on paper and still change the rhythm of the whole line.
Use line-level logic for semi-automated systems
A semi-automated line is rarely one machine in practice. It's a chain of feeders, sensors, pneumatics, tooling, guarding, controls, and operator interfaces. If you're calculating MTBF at the line level, define what counts as a failure before you start. Otherwise one team logs a jam as downtime, another logs only electrical faults, and the metric becomes noise.
For a mixed system, track failures at two levels:
- Cell-level MTBF: useful for judging total production reliability.
- Component-level MTBF: useful for finding repeat offenders like a gripper, sensor, or valve bank.
CMMS logs, maintenance work orders, and machine monitoring records are essential. If your data is weak, your MTBF will be weak. Good plants don't chase a perfect formula first. They clean up failure definitions, standardize logging, and then trend the metric over time.
MTBF and Its Relationship to Other Key Metrics
MTBF is valuable on its own, but it becomes much more useful when you put it next to the rest of your reliability picture. A machine that fails rarely can still hurt output if repairs take too long. A machine that returns to service quickly can still be a chronic disruptor if failures keep repeating.
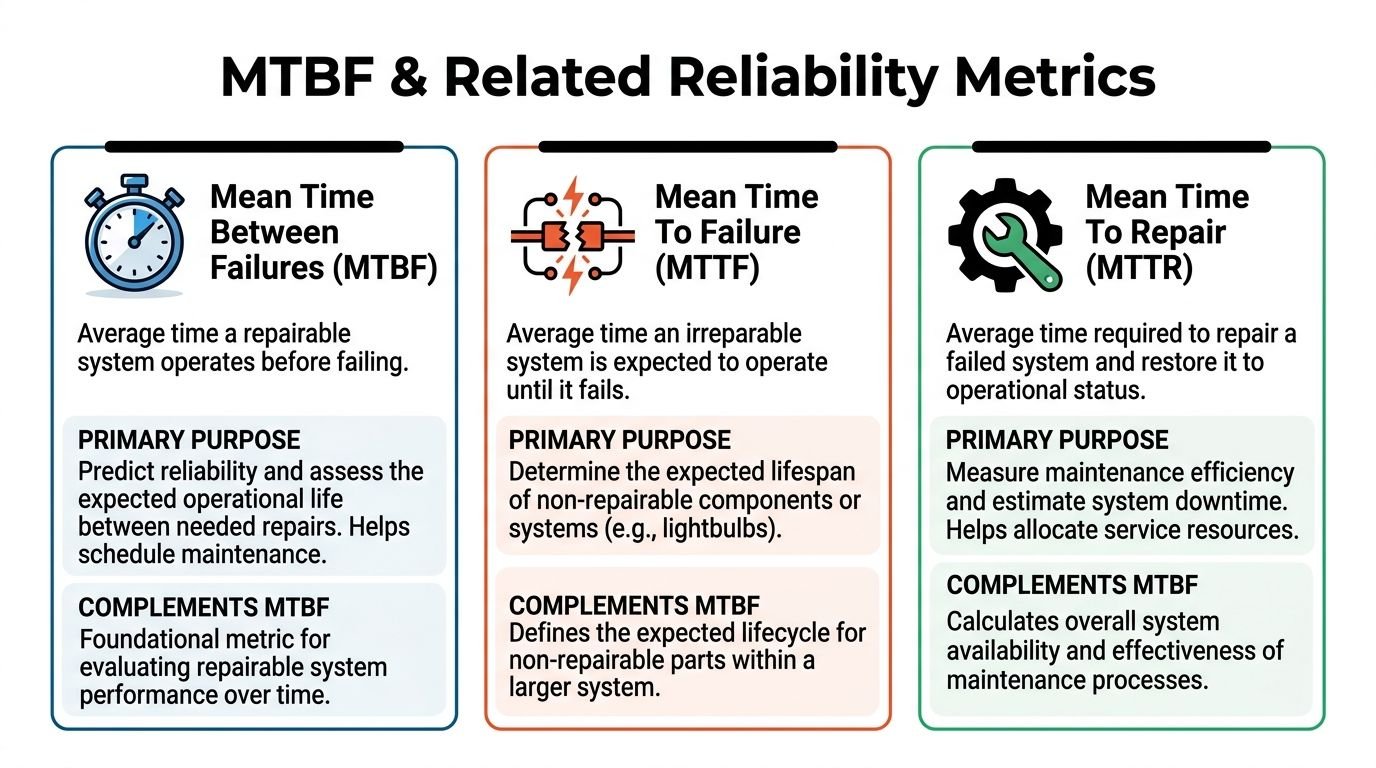
How MTBF fits with repair performance
MTBF answers one question: how often does the system fail? MTTR, or mean time to repair, answers another: how long does it take to restore function after failure?
Those two together drive the metric operators and managers care about most in daily production, which is availability. If failures are infrequent and repairs are fast, the machine spends more time in a ready-to-run state. If either one drifts in the wrong direction, availability falls.
A machine monitoring platform can make those relationships visible in real time, especially when downtime events need to be tied to actual causes rather than operator memory. That's why plants investing in machine monitoring software usually get better value from MTBF tracking than plants relying only on manual logs.
Key Reliability Metrics Compared
| Metric | What It Measures | Focus | Applies To |
|---|---|---|---|
| MTBF | Average operating time between failures | Reliability between breakdowns | Repairable systems |
| MTTF | Average operating life until failure | Replacement planning | Non-repairable items |
| MTTR | Average time to repair and restore operation | Recovery speed | Repairable systems |
The table looks simple, but the practical takeaway matters. If your production manager says, "This station doesn't fail that often," MTBF is the metric behind that statement. If maintenance says, "We can fix it quickly when it does fail," that's MTTR. Availability depends on both.
Reliability as a probability, not a promise
In reliability engineering, MTBF is the reciprocal of failure rate, expressed as MTBF = 1/λ, and it can also be used to calculate survival probability over time with P(survival) = exp^(-T/MTBF), as outlined in Wikipedia's reliability engineering entry on mean time between failures.
That matters because MTBF is often misunderstood as a guarantee. It isn't. It's a statistical way to estimate how a system behaves over time, assuming the conditions behind the model fit the equipment you're analyzing.
For a plant manager, the practical message is simple. Don't treat MTBF as a promise that the machine will definitely run until that hour mark. Treat it as a planning tool that helps you compare assets, judge risk, and improve uptime decisions.
Common Misuses and Data Pitfalls to Avoid
A bad MTBF number can be worse than no MTBF number. It gives people confidence to make the wrong call. That usually happens in two ways: teams apply the metric to the wrong asset type, or they build the calculation on messy failure data.
The biggest mistake is using MTBF for the wrong asset
The most common misuse is applying MTBF to something that isn't repairable. That error is well documented outside manufacturing too. In a 2025 industry analysis, 38% of DevOps teams were found to misreport reliability by using MTBF instead of MTTF for non-repairable assets, according to Harness's analysis of MTTF and reliability reporting.
The same mistake shows up in plants whenever teams mix machine reliability with disposable or single-use components. In medical device production, for example, the assembly machine may be repairable, but the item being processed or a single-use element in the process may not be. If those are rolled into one bucket, the reliability picture becomes distorted.
If the failed item gets replaced instead of repaired, stop calling it MTBF.
Another trap is treating cloud-like or short-lived operational entities as if they were long-lived repairable assets. Manufacturing has its own version of this problem with temporary tooling, trial builds, and short-run setups. If the lifecycle is brief or the data is incomplete, one average can hide more than it reveals.
Bad logs create false confidence
The formula only works when the failure count is trustworthy. Plants often contaminate the data in predictable ways:
- Inconsistent failure definitions: One technician logs a minor stop as a failure. Another doesn't.
- Missing operating hours: Downtime gets recorded, but uptime does not.
- Mixed asset scopes: A whole line and a single module get compared as if they were equivalent.
- Reset-driven reporting: Events vanish because operators clear faults without follow-up documentation.
MTBF is also a statistical estimate, not a lifespan label. It comes from historical behavior and assumes a useful-life period where the failure pattern is stable enough to model. That means it won't tell the whole story for assets in early commissioning, chronic wear-out, or heavily changing operating conditions.
Clean data beats complicated analysis every time. Plants get more value from a disciplined failure log and consistent asset boundaries than from a spreadsheet full of precision that nobody trusts.
Practical Strategies to Improve Your MTBF
Most plants don't improve MTBF by staring at the number. They improve it by removing the reasons equipment keeps stopping. That takes engineering discipline, maintenance discipline, and operator discipline working together.
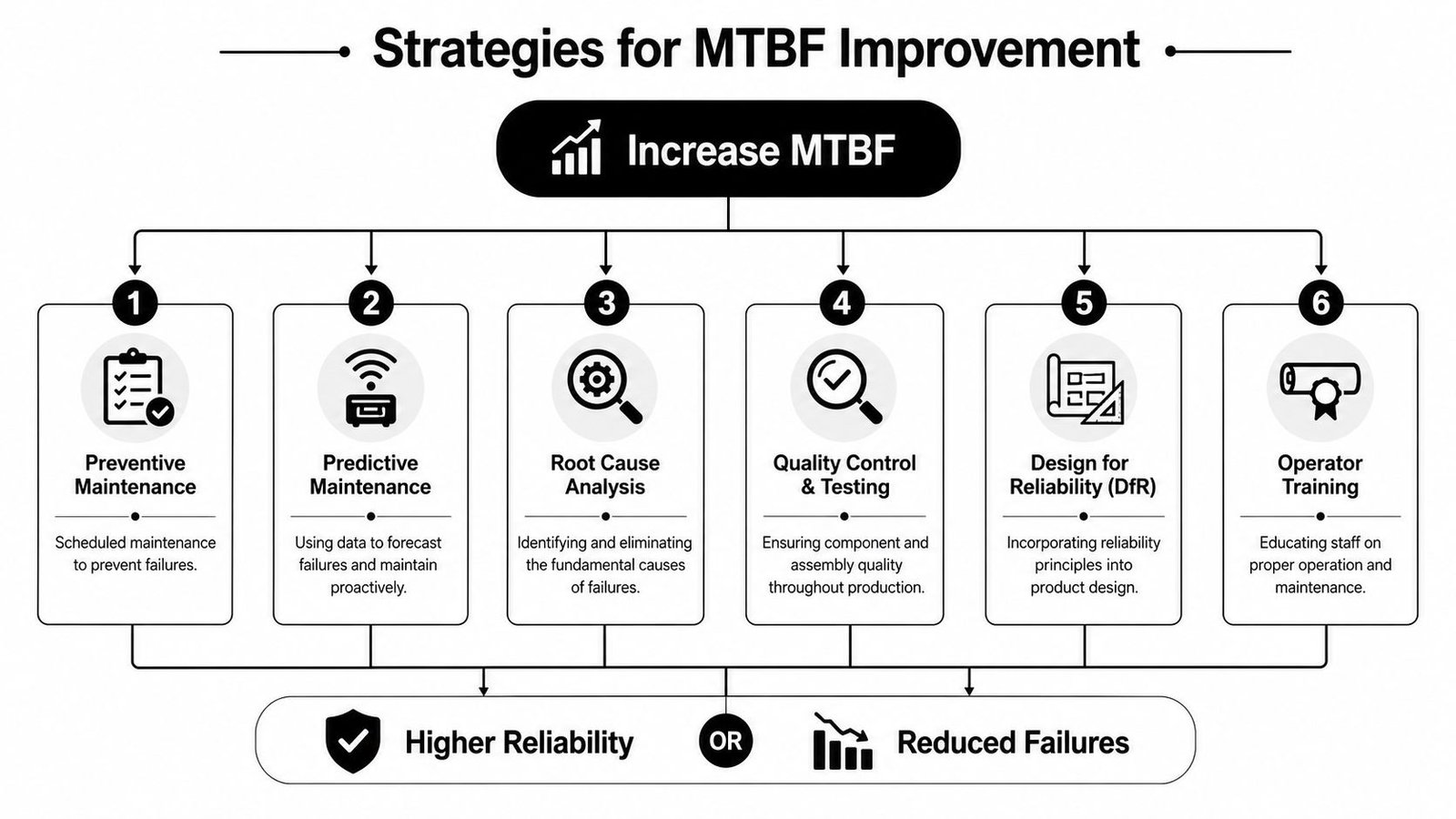
Start with failure elimination, not paperwork
If the same faults keep coming back, don't just reschedule PMs and hope the graph improves. Go after repeat causes directly.
The strongest first moves are usually these:
- Root cause analysis on repeat failures: If the same prox switch, gripper, cable path, or pneumatic component keeps causing stops, fix the underlying design or installation issue.
- Targeted preventive maintenance: Schedule interventions based on observed failure patterns, not calendar habits alone.
- Predictive checks where they fit: Use condition signals, alarms, or machine-state trends to catch degradation before the stop.
- Spare parts discipline: Keep critical wear and failure items available so a repair doesn't become a waiting exercise.
A lot of plants waste effort on broad maintenance activity when the primary issue is a short list of chronic points. One recurring cable flex problem can dominate a cell's downtime profile. One poorly mounted sensor can make an otherwise solid machine look unreliable.
Here's a concise visual overview of the reliability levers worth focusing on:
Build reliability into the machine and the operation
The biggest MTBF gains often come before the machine ever enters routine production. Good component selection, clear access for service, effective guarding, cable management, sensor placement, and controls design all influence failure frequency.
That matters even more in semi-automated systems, where flexibility is important and budgets are real. Small to mid-sized manufacturers usually can't justify overbuilt complexity. They need equipment that is reliable enough to run consistently and simple enough to maintain without a specialist for every issue.
A practical reliability program usually includes:
- Design for maintainability. If a technician can't reach the component, inspect it safely, or replace it without fighting the machine, repair quality suffers.
- Factory and site acceptance testing. FAT and SAT don't eliminate every problem, but they expose weak logic, sequencing issues, and component interactions before the line is carrying production pressure.
- Operator training. Many nuisance failures start with resets, adjustments, jams, or misuse that operators were never properly trained to handle.
- Standard work for restart and inspection. The machine should return to service the same way every time, not differently for every shift.
Better MTBF usually starts with fewer avoidable faults, not more heroic repairs.
The return is practical. Fewer stoppages mean less labor disruption, more stable throughput, and stronger confidence when deciding whether to expand, replicate, or upgrade an automation cell.
MTBF in Medical Device Manufacturing and GMP
Medical device manufacturing raises the stakes. Equipment reliability still affects throughput and labor, but it also touches validation, traceability, and process control. In that setting, sloppy reliability metrics don't just weaken maintenance planning. They create compliance risk.

Why the metric matters more in regulated production
In a GMP-aware environment, a repairable automation system should have a defensible maintenance history and failure record. That supports process consistency and helps show that the production system remains under control through its operating life. When teams execute IQ, OQ, and PQ activities, they need evidence that equipment performance isn't random and that failures are being tracked and managed systematically.
MTBF helps with that for the machine side of the process. It gives engineering, maintenance, and quality a common reliability signal for repairable equipment such as assembly stations, test fixtures, conveyors, and integrated controls. The GMP context makes documentation quality as important as the engineering itself, which is why manufacturers often need a clear understanding of what GMP means in manufacturing before reliability reporting becomes audit-ready.
Where manufacturers get into trouble
The recurring problem is metric conflation. Teams use MTBF where MTTF belongs, especially when the process includes disposable or non-repairable components. In regulated production, that weakens both technical analysis and documentation discipline.
The practical fix is to separate asset classes from the start:
- Track MTBF for repairable production equipment.
- Track MTTF for non-repairable parts or single-use items.
- Keep failure definitions controlled so engineering, maintenance, and quality use the same language.
When that structure is in place, reliability data becomes useful beyond maintenance. It supports validation work, change control decisions, spare planning, and audit conversations about process integrity.
System Engineering & Automation helps manufacturers build practical, cost-effective production systems that improve reliability, throughput, and service performance. If you're upgrading manual workstations, refining a semi-automated process, or planning GMP-aware equipment for medical device manufacturing, System Engineering & Automation provides end-to-end engineering, custom tooling, integrated controls, installation, commissioning, and ongoing support customized for real production goals and budgets.









