
If you're running a plant with aging equipment, thin maintenance coverage, and pressure to hit output every shift, you already know the problem. The line doesn't fail on a convenient schedule. It stops during a production run, during validation, or right before a shipment window.
That's why maintenance support services matter. Not as a generic add-on, and not as a vendor brochure category. In a real manufacturing environment, maintenance support has to protect uptime, fit your staffing reality, and work with the level of automation you have. For many small and mid-sized manufacturers, that means balancing manual processes, semi-automated stations, GMP documentation, and a budget that won't support a massive digital overhaul.
The practical question isn't whether support matters. It's what kind of support model will keep production moving without building a maintenance program that's more expensive and complicated than the equipment itself.
Table of Contents
- Matching Your Service Model to Your Production Reality
- Crafting Service Level Agreements That Drive Uptime
- Building Your Proactive Maintenance Framework
- Ensuring Compliance Through Training and Documentation
- Measuring Success with KPIs and ROI Analysis
- The Future of Maintenance Is Optimized Production
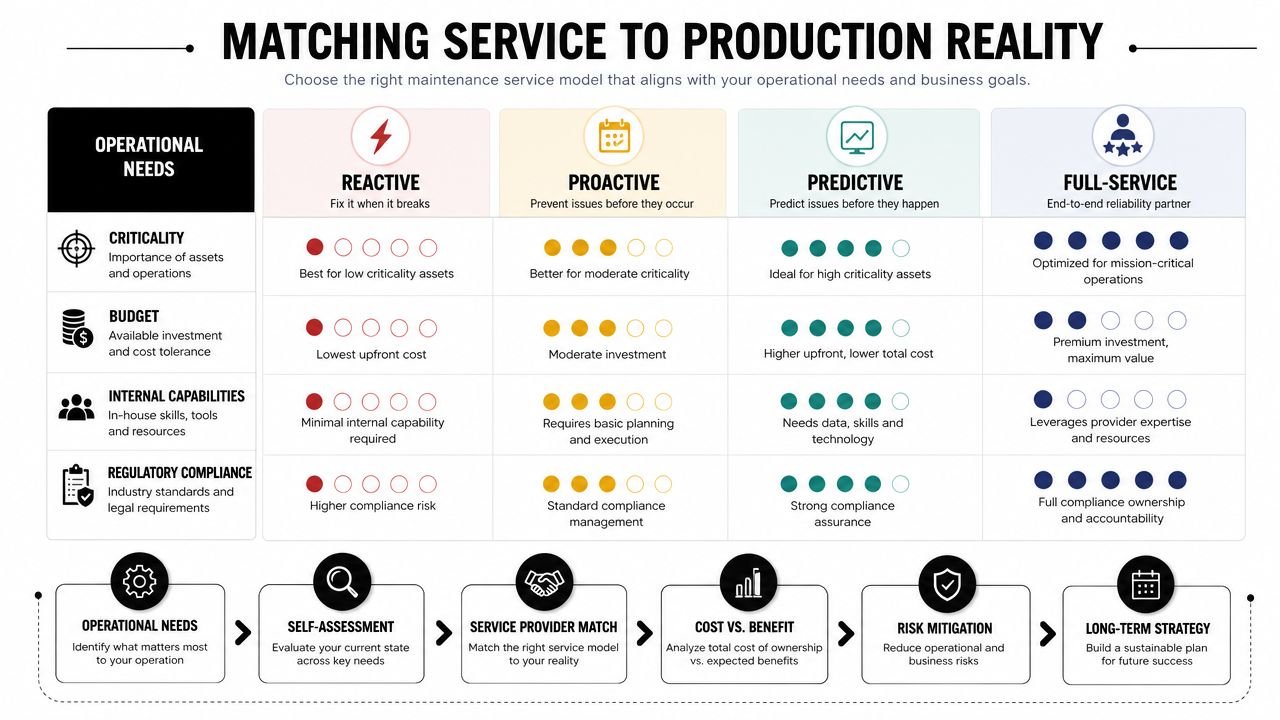
Matching Your Service Model to Your Production Reality
A line goes down at 2:10 a.m. The mechanic on shift can swap a sensor and clear a jam, but the actual fault is in the PLC logic. Production is waiting, QA is asking whether the intervention affects validated settings, and the only controls specialist is an outside contractor who has never seen this machine. That is not a maintenance problem alone. It is a service model problem.
Plants often start by comparing vendors. The better starting point is the production reality you have to support. A packaging line with one bottleneck sealer, a validated assembly cell, and a few standalone workstations needs a different support structure than a highly automated continuous process line. Small and mid-sized manufacturers feel this gap faster because they usually run with less labor cushion, tighter capital limits, and a mix of old and new equipment.
Start with asset criticality, not vendor menus
Start with three decisions that affect uptime and cost right away.
Which assets stop revenue when they fail?
The critical machine is often not the most expensive one. It is the station with no bypass, no duplicate, and no realistic manual fallback.What happens after a technician touches it?
In a GMP setting, a simple repair can trigger documentation, line clearance, setup verification, or change review. That changes who should respond and what "fast" means.Where is your in-house skill depth thin?
Many plants have solid mechanical troubleshooting and limited controls support. That is manageable if the service model covers the gap on purpose instead of leaving it to overtime and phone calls.
The practical rule is simple.
If a failure creates immediate schedule risk, quality risk, or compliance risk, support for that asset cannot depend on an informal "call someone if it breaks" process.
That is where many smaller plants incur financial losses. They buy broad coverage they rarely use, or they underbuy specialist support for the few assets that control throughput. The right answer is usually narrower and more disciplined than the sales proposal.
Choose the model that matches your plant
Three service models cover most plants.
| Service model | Where it fits | Where it breaks down |
|---|---|---|
| In-house | Stable equipment base, experienced technicians, fast access to spares | Limited controls depth, weak night/weekend coverage, inconsistent documentation |
| Outsourced | Small maintenance team, varied equipment, need for specialist help | Slow recovery if the provider does not know the line, recurring faults stay unresolved |
| Hybrid | Most small and mid-sized manufacturers | Needs clear role definition, escalation rules, and planner discipline |
For many manufacturers, the hybrid model gives the best return. Keep routine PMs, operator support, basic mechanical repairs, and daily inspection work inside the plant. Bring in outside support for controls troubleshooting, advanced root cause work, major rebuilds, and periodic system reviews.
That split fits the way many semi-automated plants run. Operators and maintenance techs handle a lot of first-response work. The outside specialist is there for the faults that can burn half a shift if the diagnosis starts from zero. If you need a system to coordinate dispatch, history, and escalation across that mix, a field service management platform for maintenance coordination can help, but only after responsibilities are defined clearly.
Labor constraints make this more important. Industry commentary summarized by Right Angle Solutions on facility maintenance labor constraints describes the pressure many plants face in skilled trades coverage. For a plant manager, the takeaway is straightforward: headcount gaps will not fix themselves, so the support model has to protect the line with the team you are able to staff.
The other mistake is chasing the most advanced maintenance strategy because it sounds modern. A full predictive stack with heavy sensor coverage and analytics can make sense on high-value, failure-sensitive assets with good data and enough engineering support. It can also turn into an expensive reporting layer on a semi-automated line that still loses most of its uptime to setup variation, worn change parts, and inconsistent fault recovery. As noted by Rebuilding Together Sacramento's discussion of maintenance strategy tradeoffs, the value of advanced programs depends on the operating context. For plants dealing with GMP limits, modest capital budgets, and mixed equipment ages, a simpler model often performs better.
Use a practical filter before adding tools or expanding contracts:
- If the line is semi-automated and operator-dependent, start with PM execution, standard fault recovery steps, and clear visual controls.
- If the process is validated, put approved intervention methods, training, and document control ahead of faster but uncontrolled access.
- If controls support is your weak point, buy access to that expertise before adding more sensors and dashboards.
- If capital is tight, remove repeat failures first. A stable line usually earns more than a complex one that the team cannot maintain.
The goal is not to copy the maintenance model used by a larger plant. The goal is to build one that fits your equipment, your staffing reality, and the cost of being down.
Crafting Service Level Agreements That Drive Uptime
A line goes down at 2:10 p.m. on the one filler that sets the pace for the whole shift. Your service provider answers within 15 minutes, which looks good on paper. The tech arrives an hour later, but he does not have the right part, does not have remote access to the PLC, and cannot touch the machine settings until QA signs off. The contract says the response target was met. Production still lost the afternoon.
That is the difference between a service agreement written for vendor activity and one written for plant recovery.
Write the SLA around production loss points
The SLA should define what the provider is responsible for restoring, what conditions have to be in place for that target to hold, and how the result will be measured. For a bottleneck asset, that usually means more than response time. It means clear expectations for triage, repair authority, spare access, escalation, and handoff back to production.

Start with the assets that hurt you when they stop. On a small or mid-sized plant floor, that is often one packaging cell, one vision station, one oven, or one legacy machine that nobody wants to replace yet. Write the agreement around those failure points first. A plant-wide SLA that treats every asset the same usually wastes money on low-impact equipment and still leaves primary constraints vague.
Use contract terms that operations, maintenance, and quality will interpret the same way:
- Critical asset definition: Name the exact machines, controls cabinets, utilities, and subsystems covered under priority support.
- Restoration standard: State whether service ends at temporary operation, normal production rate, or approved release for a validated process.
- Escalation path: Define when the provider moves from general troubleshooting to controls support, OEM involvement, or on-site specialist response.
- Parts ownership: Specify which spares the plant stocks, which the provider stocks, and what can be substituted without engineering or quality review.
- Documentation requirements: List the service record, parts traceability, calibration impact, and change documentation required before closing the job.
For GMP lines, the wording matters. A fast repair that bypasses documentation can create a larger problem than the original stoppage. If a technician changes a parameter, swaps a critical component, or loads code without the right approval path, the plant may get the machine running and still lose time to investigation, review, or re-verification.
If you need tighter control over dispatch, work order history, and technician accountability, a tool such as IFS field service management software for plant service workflows can help structure the process around actual response requirements instead of email chains and handwritten notes.
What good and bad SLA language looks like
The strongest clauses remove interpretation. They make it clear what happens during a stop, who does what, and what counts as done.
Response time measures attendance. Recovery language measures whether production can actually resume.
Weak clause
Provider will respond to service calls within an agreed window.
Better clause
Provider will acknowledge critical stoppages immediately, start remote triage when available, dispatch personnel qualified for the fault category, and document cause, corrective action, and recommended follow-up before the work order is closed.
Weak clause
Provider will perform preventive maintenance as needed.
Better clause
Provider will complete scheduled PM tasks on covered assets according to the approved maintenance plan, record task completion and exceptions, and identify any work that requires quality, safety, or validation review before execution.
For regulated operations, add explicit controls in the contract:
| SLA area | What to include |
|---|---|
| Change control | Who can adjust settings, replace components, modify recipes, or change code |
| Documentation | Required service record content, review steps, and approval path |
| Validation impact | What maintenance actions trigger review, re-verification, or QA involvement |
| Access control | Which technicians are authorized for regulated equipment and under what conditions |
Good SLAs also assign responsibilities back to the plant. If the provider is expected to hit recovery targets, the plant has to maintain current drawings, approved backups, spare parts discipline, and clear access rules. I have seen plants demand aggressive uptime terms while keeping no tested PLC backup, no labeled spare servo, and no approved after-hours quality contact. The contract did not fail in those cases. The setup did.
A useful SLA reflects the trade-off. Higher coverage, stocked spares, and controls expertise cost more. For a semi-automated plant with tight budgets, it often makes more sense to buy stronger coverage on a few production-critical assets than broad but shallow support across everything.
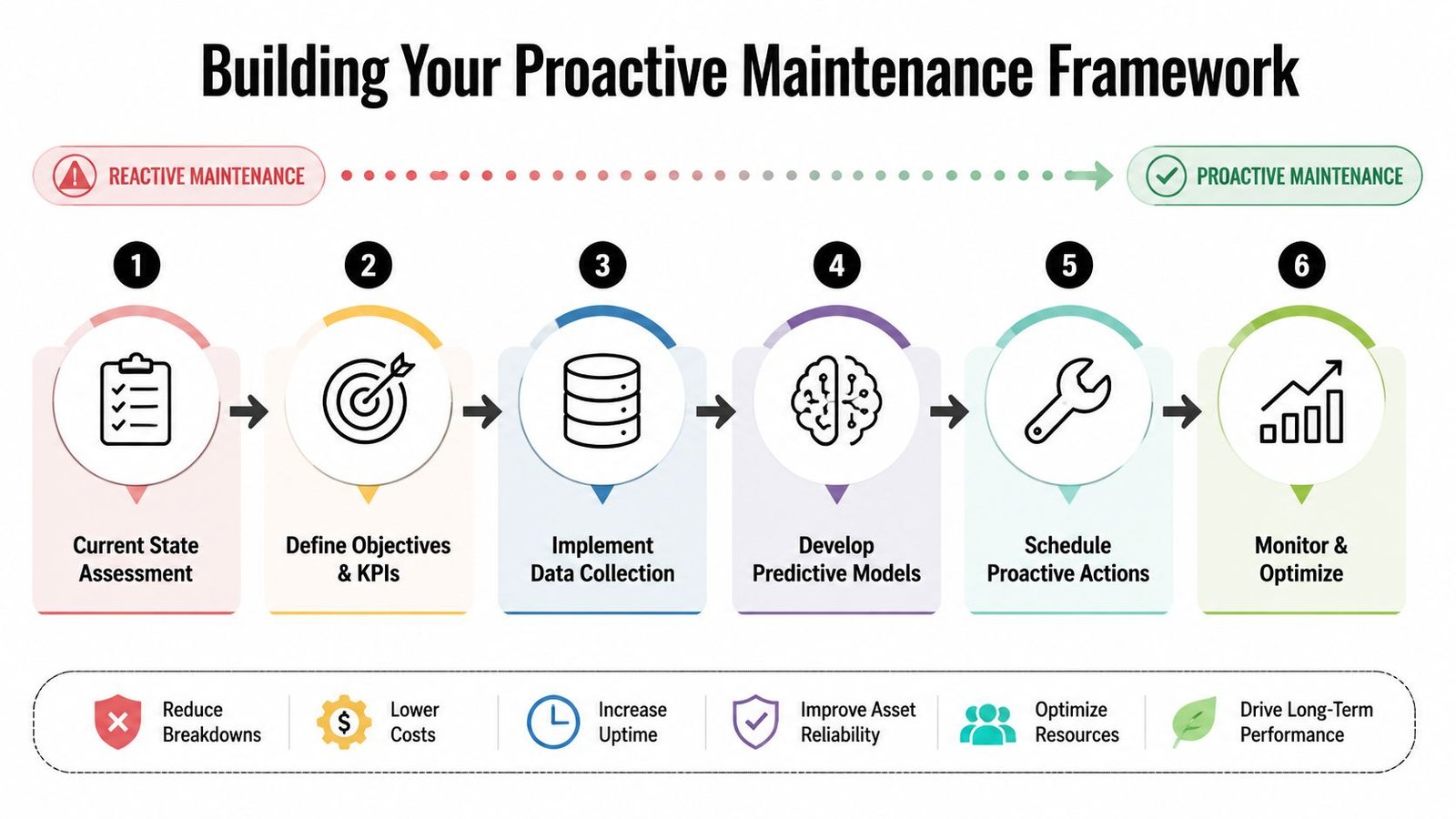
Building Your Proactive Maintenance Framework
Reactive maintenance always feels cheaper until the line starts failing in clusters. Then you pay in scrap, missed schedule, emergency labor, and distracted supervision.
A stronger framework starts with a simple shift in logic. Don't ask how fast your team can respond. Ask what failure pattern you can detect early enough to prevent the stop.
Build the framework around actual failure modes
Preventive and predictive work have a clear business case when they're used in the right place. According to the U.S. Department of Energy, predictive maintenance can save roughly 8% to 12% over preventive maintenance and up to 40% over reactive maintenance, as reported by UpKeep's maintenance statistics summary. The same source notes that every $1 of deferred maintenance can grow to about $4 in later capital renewal costs. That's why a plant that delays maintenance to “save money” often creates a larger capital problem later.
Start with a ranked equipment list and define one maintenance approach for each asset class:
- Run to condition for low-risk items that don't affect throughput or quality.
- Scheduled PM for wear items with known service intervals.
- Condition-based checks for assets that show measurable degradation.
- Specialist intervention for controls, servo, vision, or validated systems where the wrong adjustment creates larger problems.
Many plants overcomplicate the program. You don't need predictive analytics on every motor and cylinder. You need early warning on the assets that can shut the plant down or create a deviation.
A practical system can include operator checks, PM work orders, fault-code review, and selected sensor inputs. For some manufacturers, a tool such as machine monitoring software fits as one layer in that system, especially when the goal is better visibility into downtime patterns rather than a full digital transformation.
Connect scheduling, people, and remote visibility
The technical side only works if the human side is built at the same time. A PM schedule that exists in a spreadsheet but isn't understood by technicians won't change performance.
A proactive framework needs these operating pieces tied together:
Onboarding by machine family
Every technician should know the machine function, common failure points, lockout requirements, setup-sensitive adjustments, and what changes require approval.Remote diagnostics where they pay off
Use remote access and alarm review for controls-heavy equipment when it cuts troubleshooting time. Don't force it onto simple equipment that can be diagnosed faster in person.Spare parts by consequence, not catalog size
Stock the parts that create long outages when missing. Don't fill shelves with low-risk items you can source quickly.Feedback loop after every fault
If the same fault repeats, the schedule, the component choice, or the training is wrong. Proactive maintenance depends on closing that loop.
The plants that get value from maintenance support services are rarely the ones with the fanciest dashboards. They're the ones that turn each failure into a better standard.
System Engineering & Automation is one example of a provider that supports this kind of practical framework by working across semi-automatic, manual, and fully automated equipment while aligning solutions to budget and production goals.
Ensuring Compliance Through Training and Documentation
In regulated manufacturing, maintenance isn't just about getting the machine back on. It's about restoring it in a way that can survive an audit, support product quality, and make sense to the next technician who touches it.
In regulated plants, maintenance is an auditable process
A poorly documented repair can cost more than the downtime that triggered it. The machine may run, but the plant can still end up with unclear settings, missing traceability, inconsistent setup, or a validation question no one can answer cleanly.
That's why training and documentation are operational controls, not administrative overhead. In GMP environments, every maintenance action should follow approved steps, define what can be adjusted, and show what evidence must be recorded before release. If your team needs a primer on the regulatory context, this overview of GMP in manufacturing is a useful reference point.
Condition-based maintenance adds another layer of discipline. Advanced programs often monitor vibration, temperature, infrared, ultrasound, runtime hours, and threshold alarms, then trigger work orders when readings move beyond a defined limit, according to CityFM's preventive maintenance guidance. That work is scheduled around the P-F interval, the window between potential failure and functional failure.
The catch is simple. If technicians don't understand what readings matter, how thresholds were set, and what action is allowed, the data won't protect you.
What documentation needs to exist before the next breakdown
Use a documentation stack that matches the way your equipment is maintained.
SOPs for recurring tasks
Write step-by-step instructions for PMs, calibration-related checks, change-part adjustments, and restart verification. Keep them specific to the machine, not generic to the department.Machine-specific troubleshooting guides
Include fault descriptions, likely causes, approved checks, and escalation triggers. This is especially useful on semi-automated systems with custom fixtures and controls.Training records by equipment type
Don't just record that a technician attended training. Record which machine family, which procedures, and which intervention limits they were approved for.Service and change logs
Capture what failed, what was changed, which part was used, whether settings moved, and whether quality or engineering reviewed the action.
If a repair changes how a machine behaves, and you can't reconstruct what happened later, you don't have a maintenance process. You have a memory problem.
This discipline protects ROI too. Plants lose time when experienced technicians leave and take machine knowledge with them. A strong documentation system turns tribal knowledge into a repeatable operating standard.
Measuring Success with KPIs and ROI Analysis
A maintenance program isn't successful because spending went down. It's successful when production becomes more predictable, failures become easier to recover from, and fewer problems reach operators in the first place.
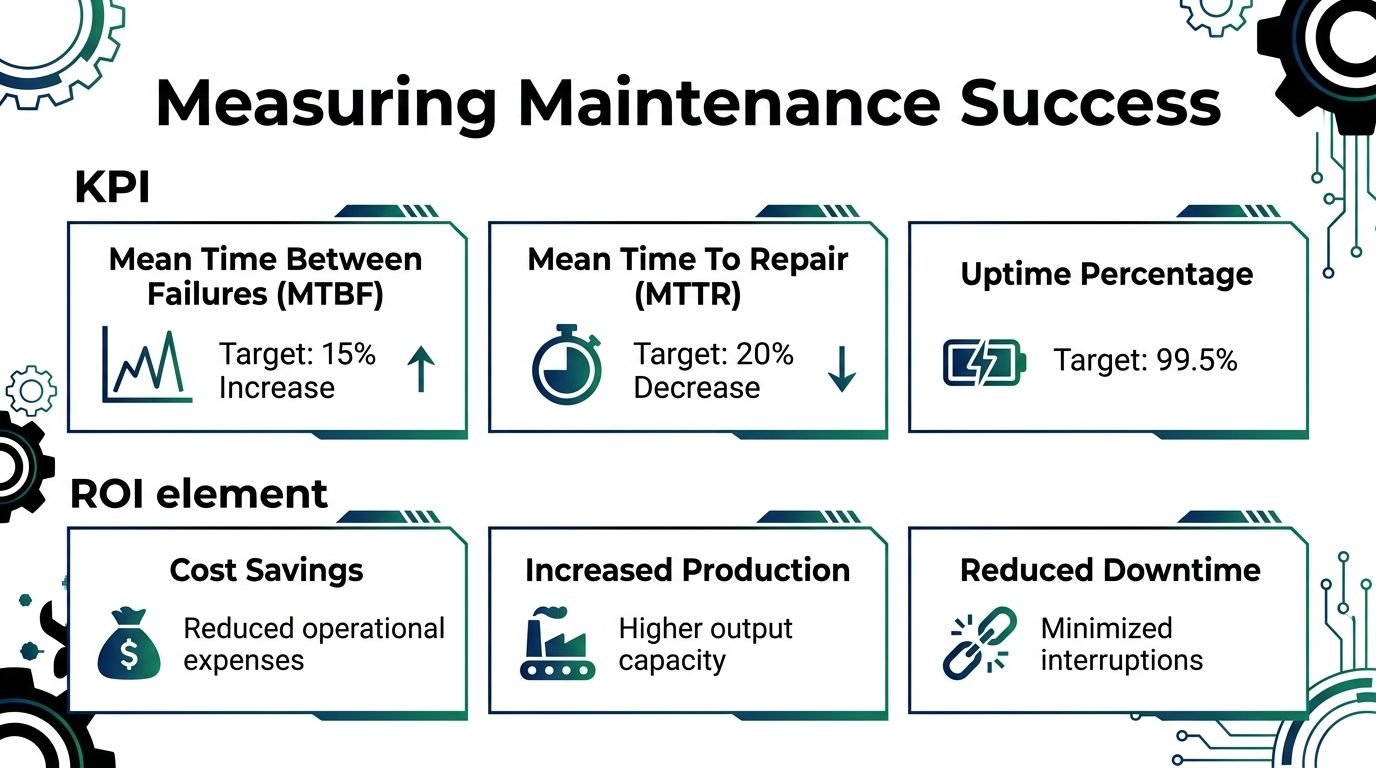
Track fewer metrics and use them harder
The most useful KPI set is small. A high-performing maintenance program should focus on 3 to 5 critical metrics such as OEE, MTBF, and Planned Maintenance Percentage, according to MaintainX guidance on maintenance KPIs. That same source notes that an OEE above 90% is considered world class, while values above 70% are generally acceptable.
For most plants, the core set looks like this:
| KPI | What it tells you | Simple interpretation |
|---|---|---|
| MTBF | How long equipment runs between failures | Rising means reliability is improving |
| MTTR | How long it takes to restore function | Rising means diagnosis, access, parts, or skill is weak |
| PMP | Share of maintenance time that is planned | Low values usually mean the team is trapped in firefighting |
| OEE | Availability, performance, and quality in one view | Useful for seeing whether maintenance is helping production, not just closing tickets |
The key is not just tracking the number. It's connecting the trend to action.
- If MTBF falls, review recurring failure modes, component quality, lubrication practices, and operator misuse.
- When MTTR rises, look at fault isolation, spare access, service documentation, and whether technicians have the right skill mix.
- If PMP stays low, your maintenance schedule may be unrealistic, or production may be crowding out planned work.
- When OEE stalls, don't assume maintenance is the only cause. Check setup losses, minor stops, and process instability too.
Turn KPI trends into operating decisions
A lot of teams collect maintenance data and never use it to change behavior. That is the fundamental failure.
Good KPI review usually answers one of these questions:
- Should this asset stay on calendar PM or move to condition-based checks?
- Do we need a stocked spare, a redesign, or better technician training?
- Is an outside specialist justified, or can the internal team own this failure mode?
- Is the plant accepting too much deferred maintenance risk?
MaintainX also points out common pitfalls: tracking too many metrics, and relying on manual data entry instead of mobile, real-time capture. In practice, that matters because bad data creates false confidence. If work orders are closed late, coded inconsistently, or missing downtime context, the KPI trend won't support sound decisions.
Field note: If supervisors can't explain what action they'll take when a KPI moves the wrong direction, the metric is decoration.
ROI analysis should stay grounded. Count avoided downtime, better schedule adherence, fewer emergency callouts, reduced repeat failures, and more stable output. That's usually enough to judge whether your maintenance support services are improving the business.
The Future of Maintenance Is Optimized Production
At 2:00 a.m., the line is down, the night crew is waiting, and the only technician who knows that filler well is at home. In that moment, the question is not whether the plant has a maintenance program. The question is whether maintenance support was set up to protect production under real operating conditions.
That is where this discussion ends for small and mid-sized manufacturers. The future is not more maintenance activity. It is more predictable output from the people, equipment, and budget you already have.
For some plants, that means outsourcing specialist work on controls, vision systems, or validation-heavy equipment while keeping routine PMs in-house. For others, it means resisting the urge to buy full predictive platforms before the team can execute basic inspection routes, parts control, and documentation. In GMP environments, the right answer often includes more disciplined records and change control before it includes more sensors.
The plants that improve usually make a few practical choices. They rank assets by production risk, not by replacement cost alone. They support semi-automated lines differently than fully automated ones, because operator interaction, setup variation, and manual handling change the failure pattern. They also accept trade-offs. A lower-cost service model can work well if the response scope, spare parts plan, and escalation path are clear. A premium support contract can still disappoint if the provider does not understand sanitation windows, batch constraints, or validated settings.
Optimized production comes from maintenance decisions that fit the operation. That means fewer avoidable stops, faster recovery when failures happen, and less disruption to quality and scheduling.
If you're evaluating maintenance support services alongside automation upgrades, custom tooling, or semi-automated production improvements, System Engineering & Automation works with manufacturers to align equipment design, support planning, and real-world production constraints. The focus is practical execution: solutions that fit budget, support GMP-aware operations, and improve reliability without overbuilding the system.









